从上往下看的源码,标注了路上一些“景点”。皮皮虾,我们走。
1 2 3 4 5 6 7 8 9 10 11 12 13
| * Constructs a new hashtable with the same mappings as the given * Map. The hashtable is created with an initial capacity sufficient to * hold the mappings in the given Map and a default load factor (0.75). * * @param t the map whose mappings are to be placed in this map. * @throws NullPointerException if the specified map is null. * @since 1.2 */ public Hashtable(Map<? extends K, ? extends V> t) { this(Math.max(2*t.size(), 11), 0.75f); putAll(t); }
|
initialCapacity不指定的话是默认11;
这里单独列出这个初始化方法,主要是因为这个2*t.size(),如果你还记得的话,在第二路文中介绍HashMap.resize()时,它就是按2扩容的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
| * Returns an enumeration of the keys in this hashtable. * * @return an enumeration of the keys in this hashtable. * @see Enumeration * @see #elements() * @see #keySet() * @see Map */ public synchronized Enumeration<K> keys() { return this.<K>getEnumeration(KEYS); } private static final int KEYS = 0; private static final int VALUES = 1; private static final int ENTRIES = 2;
|
看到synchronized想说的是HashTable是同步,所以大多数方法都可见进行了同步处理,这点与HashMap不同(其他差别:HashTable的key、value都不允许为null)。该方法通过Enumeration遍历Hashtable的键(KEYS是定义的全局变量),类似的,还有通过Enumeration遍历Hashtable的值。感兴趣的同学可以继续跟getEnumeration(),它返回的是一个hashtable内部实现的Enumerator类(实现了Enumeration, Iterator)。
应用实例如下:
1 2 3 4
| Enumeration enu = table.keys(); while(enu.hasMoreElements()) { System.out.println(enu.nextElement()); }
|
1 2 3 4 5 6 7
| * The maximum size of array to allocate. * Some VMs reserve some header words in an array. * Attempts to allocate larger arrays may result in * OutOfMemoryError: Requested array size exceeds VM limit */ private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
|
这里好奇的是“-8”从何而来?从stackoverflow得到的答案是(译):
数组(ARRAY)需要用8bytes来存储(2^31 = 2,147,483,648 )大小(size)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37
| * Increases the capacity of and internally reorganizes this * hashtable, in order to accommodate and access its entries more * efficiently. This method is called automatically when the * number of keys in the hashtable exceeds this hashtable's capacity * and load factor. */ @SuppressWarnings("unchecked") protected void rehash() { int oldCapacity = table.length; Entry<?,?>[] oldMap = table; int newCapacity = (oldCapacity << 1) + 1; if (newCapacity - MAX_ARRAY_SIZE > 0) { if (oldCapacity == MAX_ARRAY_SIZE) return; newCapacity = MAX_ARRAY_SIZE; } Entry<?,?>[] newMap = new Entry<?,?>[newCapacity]; modCount++; threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1); table = newMap; for (int i = oldCapacity ; i-- > 0 ;) { for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) { Entry<K,V> e = old; old = old.next; int index = (e.hash & 0x7FFFFFFF) % newCapacity; e.next = (Entry<K,V>)newMap[index]; newMap[index] = e; } } }
|
hashtable的新容量是:2倍+1,即始终为奇数。不同于前2回讲过的hashmap中resize()则是2倍。why?我们知道“除2以外所有的素数都是奇数”,而当哈希表的大小为素数时,简单的取模哈希的结果分布更加均匀,从而降低哈希冲突。
“0x7FFFFFFF”即二进制的32个1,按位与运算后使得结果范围在区间[0,2147483647]内,可以理解为取正。
此外,for循环中的新旧数据迁移的5行代码也很经典。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| * Creates a shallow copy of this hashtable. All the structure of the * hashtable itself is copied, but the keys and values are not cloned. * This is a relatively expensive operation. * * @return a clone of the hashtable */ public synchronized Object clone() { try { Hashtable<?,?> t = (Hashtable<?,?>)super.clone(); t.table = new Entry<?,?>[table.length]; for (int i = table.length ; i-- > 0 ; ) { t.table[i] = (table[i] != null) ? (Entry<?,?>) table[i].clone() : null; } t.keySet = null; t.entrySet = null; t.values = null; t.modCount = 0; return t; } catch (CloneNotSupportedException e) { throw new InternalError(e); } }
|
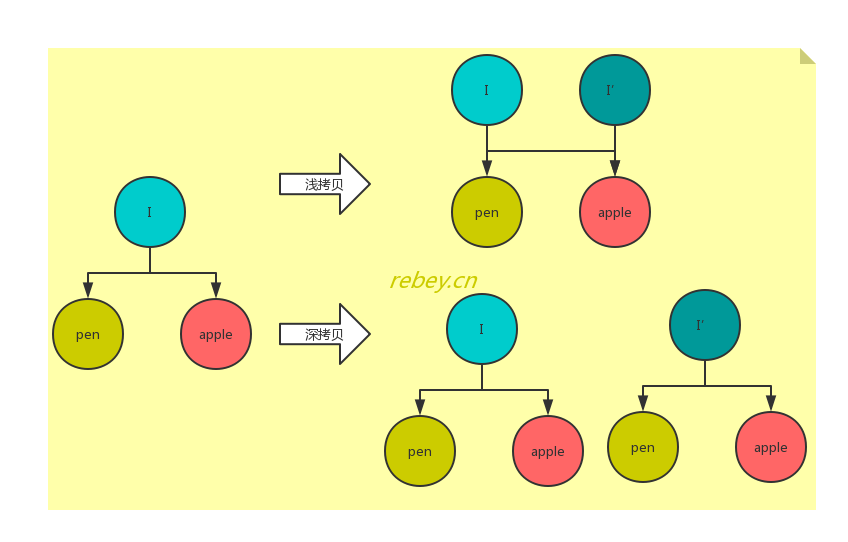
“shallow copy”一词成功引起了笔者注意。what is it?浅拷贝非java独有的概念,其他编程语言同样存在,如C#、C++、IOS、python等。与之对应的是深拷贝(deep copy)。两者的区别是:
对象的浅拷贝会对“主”对象进行拷贝,但不会复制主对象里面的对象。”里面的对象“会在原来的对象和它的副本之间共享。深拷贝是一个整个独立的对象拷贝。[参考文献2]
“I have a pen, I have a apple.”(唱起来了) 我,笔,苹果是三个对象,我引用了笔和苹果,此时对我进行拷贝,效果如图:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
| public class Apple { String color; public String getColor() { return color; } public void setColor(String color) { this.color = color; } } Apple apple = new Apple(); apple.setColor("red"); Hashtable ht = new Hashtable(); ht.put("apple", apple); System.out.println(((Apple)ht.get("apple")).getColor()); Hashtable htc = (Hashtable) ht.clone(); System.out.println(((Apple)htc.get("apple")).getColor()); ((Apple)htc.get("apple")).setColor("green"); System.out.println(((Apple)ht.get("apple")).getColor()); System.out.println(((Apple)htc.get("apple")).getColor());
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
| * Returns a string representation of this <tt>Hashtable</tt> object * in the form of a set of entries, enclosed in braces and separated * by the ASCII characters "<tt>, </tt>" (comma and space). Each * entry is rendered as the key, an equals sign <tt>=</tt>, and the * associated element, where the <tt>toString</tt> method is used to * convert the key and element to strings. * * @return a string representation of this hashtable */ public synchronized String toString() { int max = size() - 1; if (max == -1) return "{}"; StringBuilder sb = new StringBuilder(); Iterator<Map.Entry<K,V>> it = entrySet().iterator(); sb.append('{'); for (int i = 0; ; i++) { Map.Entry<K,V> e = it.next(); K key = e.getKey(); V value = e.getValue(); sb.append(key == this ? "(this Map)" : key.toString()); sb.append('='); sb.append(value == this ? "(this Map)" : value.toString()); if (i == max) return sb.append('}').toString(); sb.append(", "); } }
|
“(this Map)”,即,ht.put(ht, ht)将输出{(this Map)=(this Map)}。
还有同步处理用到的volatile关键字(各个线程在访问该关键字所修饰变量前必须从主存(共享内存)中读取该变量的值)、Collections.synchronizedSet()(创建同步的集合对象)有缘再续。
参考文献[推荐]:
1.HashMap和HashTable到底哪不同?,2016-07-05;
2.Java 中的浅拷贝与深拷贝(Shallow vs. Deep Copy in Java ),中英;
3.Java基础之volatile关键字,2016-07-18;

