前言
本文以jdk1.8中HashMap.putAll()方法为切入点,分析其中难理解、有价值的源码片段(类似ctrl+鼠标左键查看的源码过程)。✈观光线路图:putAll() –> putMapEntries() –> tableSizeFor() –> resize() –> hash() –> putVal()…
将涉及到的源码全局变量:
transient Node
final float loadFactor; 负载因子(默认0.75),表示table的填满程度。
static final int MAXIMUM_CAPACITY = 1 << 30; 最大容量
int threshold; 阈值 = table.length loadFactor(160.75=12)
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; 初始16
static final float DEFAULT_LOAD_FACTOR = 0.75f;
前置知识:
- ? extends K: 泛型通配符
好了,带全设备、干粮,准备出发~
putAll
|
|
putMapEntries
|
|
tableSizeFor
|
|
这里的“-1”可以理解为是为了++保证结果值≥原值++。举个栗子,假如cap=8(1000)。计算结果为16(10000)。这显然不是我们想要的最小的2的幂。
关于抑或、右移的计算过程,我以size=3为例,可以参考便于理解: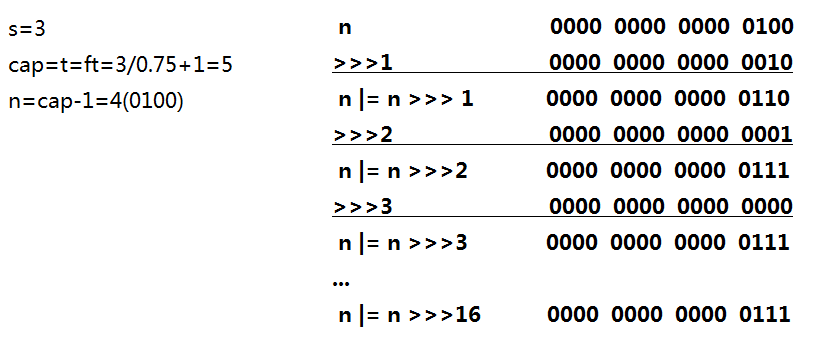
不对啊,图里算出来的结果等于7啊,说好的2的幂呢?别忘了这里return最后在返回值进行了+1。
那么问题来了。为什么要遵循“2的幂次方”的套路呢?不仅tableSizeFor如此,连一些参数初始值也暗含类似意图(如DEFAULT_INITIAL_CAPACITY = 1 << 4)。
根本目的为了提高效率,为了使用借助以下规律:
取余(%)操作中如果除数是2的幂次方,则等同于与其除数减一的与(&)操作
因此在源码中会看到大量的“(n - 1) & hash”语句,也就是为什么要按“2的幂次方”的套路出牌了。
resize
|
|
hashMap起初使用链表法避免哈希冲突(相同hash值),当链表长度大于TREEIFY_THRESHOLD(默认为8)时,将链表转换为红黑树,当然小于UNTREEIFY_THRESHOLD(默认为6)时,又会转回链表以达到性能均衡。
根据“e.hash & oldCap”是否为零将原链表拆分成2个链表,一部分仍保留在原链表中不需要移动,一部分移动到“原索引+oldCap”的新链表中。
那么问题来了,“e.hash & oldCap”从何而来!?
因为扩容前后hash(key)不变,oldCap与newCap皆为“2的幂次方”,则++newCap-1的二进制最高位与oldCap最高位相同++。结合上文“index=(n-1)&hash”可知:新的index的取决于:++(n-1)二进制最高位上是0还是1++;因此源码作者巧妙的拉关系,以“oldCap等价于newTab的(n-1)的最高位”推出“e.hash & oldCap”!
假设我们length从16resize到32(以下仅写出8位,实际32位),hash(key)是不变的。下面来计算一下index:
n-1: 0000 1111—–》0001 1111【高位全0,&不影响】
hash1: 0000 0101—–》0000 0101
index1: 0000 0101—–》0000 0101【index不变】
hash2: 0001 0101—–》0001 0101
index2: 0000 0101—–》0001 0101【新index=5+16即原index+oldCap】hash
|
|
异或运算:(h = key.hashCode()) ^ (h >>> 16)
原 来 的 hashCode : 1111 1111 1111 1111 0100 1100 0000 1010
移位后的hashCode: 0000 0000 0000 0000 1111 1111 1111 1111
进行异或运算 结果:1111 1111 1111 1111 1011 0011 1111 0101这样做的好处是,可以将hashcode高位和低位的值进行混合做异或运算,而且混合后,低位的信息中加入了高位的信息,这样高位的信息被变相的保留了下来。掺杂的元素多了,那么生成的hash值的随机性会增大。
putVal
参考文献:
- HashMap源码注解 之 静态工具方法hash()、tableSizeFor()(四);201604
- 源码分析之HashMap;201704
- 【集合详解】HashMap源码解析;201608
- HashMap源码分析(jdk1.8);201604
更多有意思的内容,欢迎访问笔者小站: rebey.cn

